Useful Scripts
Some useful scripts for generating manifest files for use in https://github.com/M3-org/characterstudio. YMMV.
Adding Your Own Traits
This is for the typical usecase of creating your own avatar builder with your traits, like you see on the left side of the screenshot below.
Note: You'll need to generate your own screenshots. I recommend screenshot-glb which works with VRM files as well and keep the base filenames same as the VRM files.
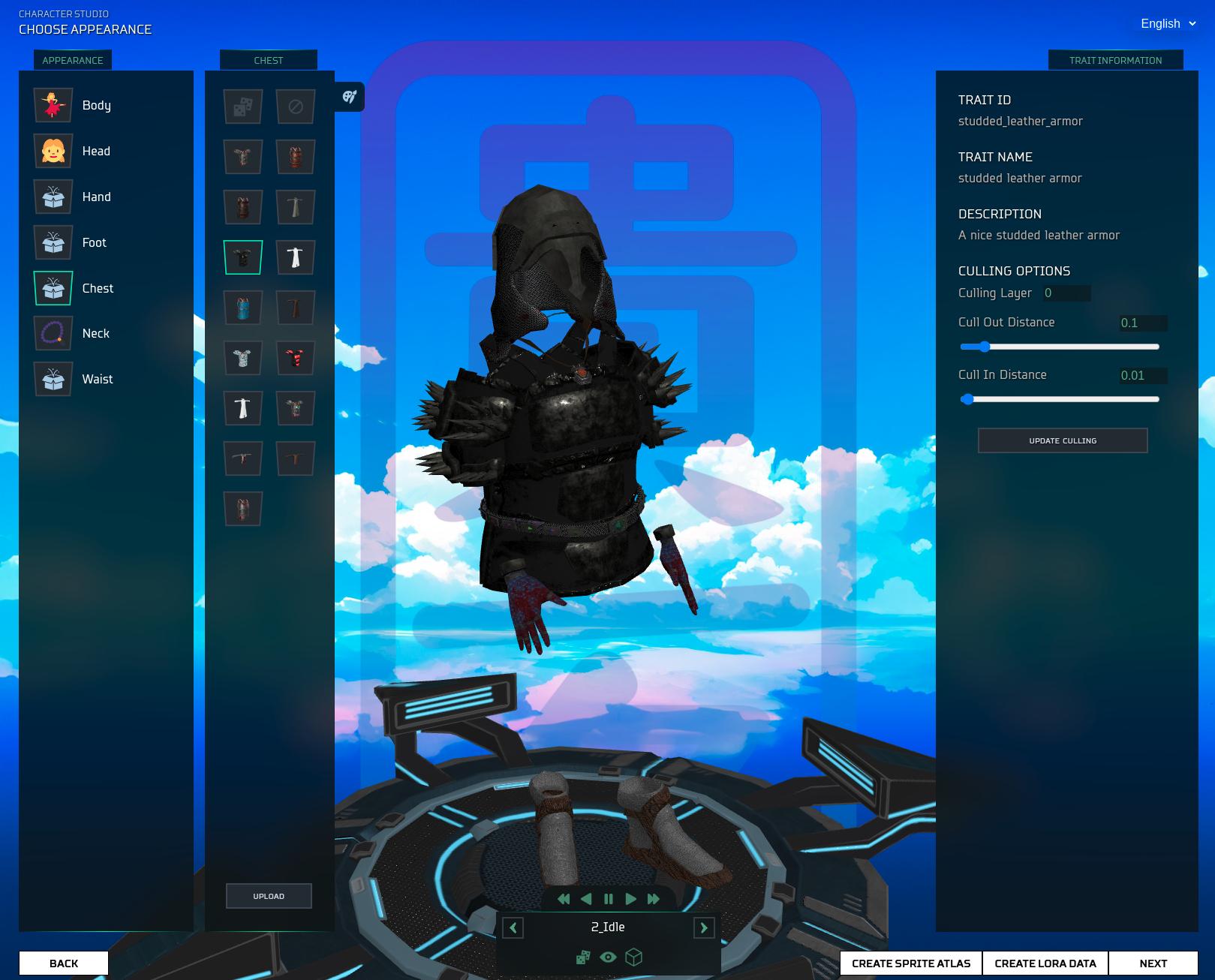
You will need to modify the paths for the templates, it's currently configured for https://github.com/m3-org/loot-assets.
Here is how the folder structure looks before generating manifest.json
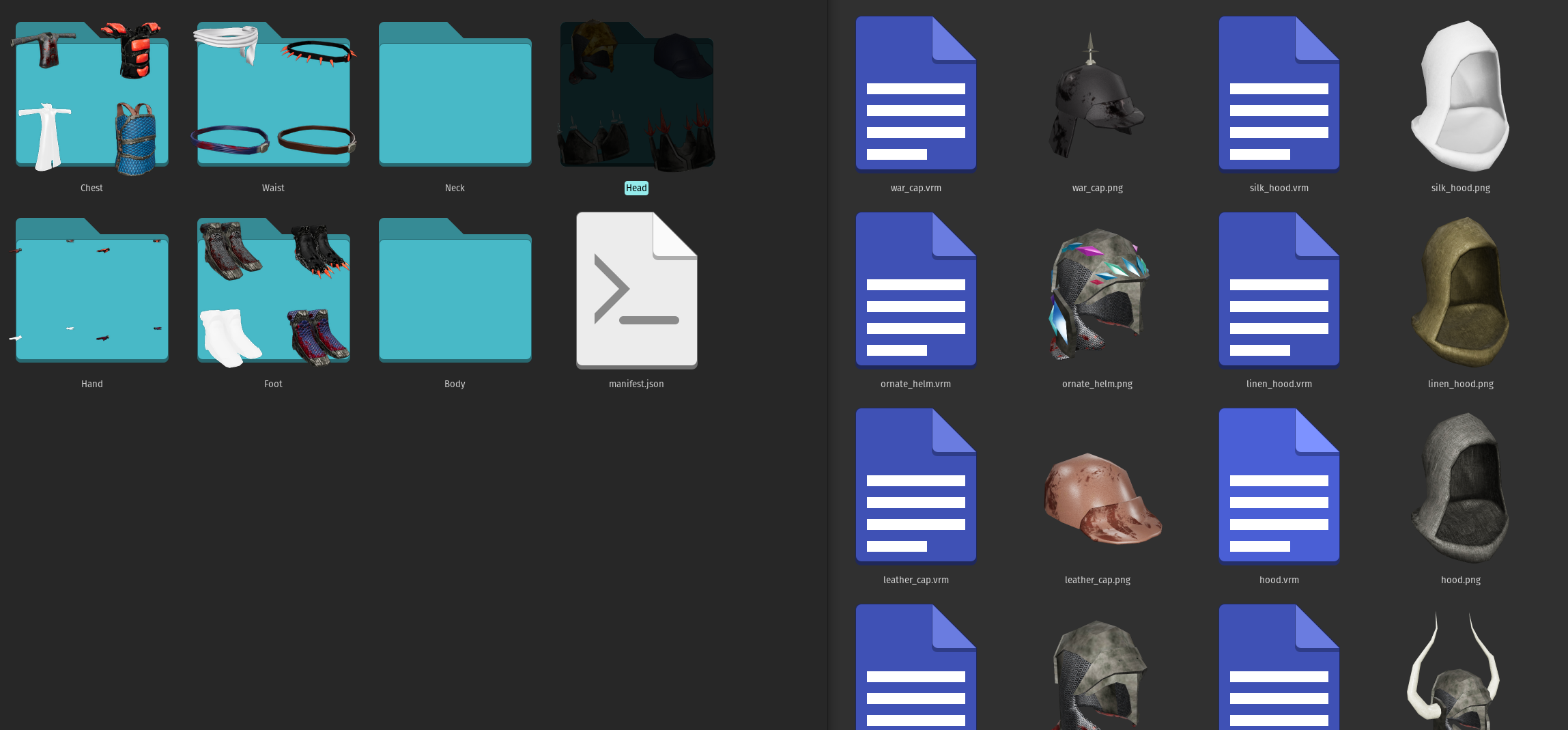
This is the script I'm using for generating a manifest for https://github.com/m3-org/loot-assets
import os
import json
def generate_manifest(directory_path):
manifest_template = {
"assetsLocation": "./loot/",
"format": "vrm",
"traitsDirectory": "./loot/models/",
"thumbnailsDirectory": "./loot/models/",
"exportScale": 1,
"animationPath": get_animation_paths(),
"traitIconsDirectorySvg": "./loot/icons/",
"defaultCullingLayer": -1,
"defaultCullingDistance": [0.1, 0.01],
"initialTraits": ["Body", "Head", "Hand", "Foot", "Chest", "Waist", "Neck"],
"offset": [0.0, 0.48, 0.0],
"traits": generate_traits(directory_path),
"textureCollections": [],
"colorCollections": []
}
return json.dumps(manifest_template, indent=2)
def get_animation_paths():
animation_directory = "./animations"
animation_paths = [os.path.join(animation_directory, file) for file in os.listdir(animation_directory) if file.endswith(".fbx")]
return sorted(animation_paths)
def generate_traits(directory_path):
traits = []
trait_culling_layers = {
"Body": 0,
"Head": -1,
"Hand": -1,
"Foot": -1,
"Chest": 0,
"Neck": -1,
"Waist": -1
}
for trait_name, culling_layer in trait_culling_layers.items():
trait = {
"trait": trait_name,
"name": trait_name.capitalize(),
"icon": "",
"type": "mesh",
"iconGradient": "",
"iconSvg": f"{trait_name.upper()}.svg",
"cullingLayer": culling_layer,
"cameraTarget": {"distance": 3.0, "height": 0.8},
"cullingDistance": [0.1, 0.01],
"collection": generate_collection(directory_path, trait_name)
}
traits.append(trait)
return traits
def generate_collection(directory_path, trait_name):
trait_directory_path = os.path.join(directory_path, trait_name)
return [
{
"id": entry[:-4],
"name": entry[:-4].replace("_", " "),
"directory": f"{trait_name}/{entry}",
"thumbnail": f"{trait_name}/{entry[:-4]}.png"
}
for entry in os.listdir(trait_directory_path)
if entry.endswith(".vrm")
]
if __name__ == "__main__":
directory_path = "./models/"
manifest_content = generate_manifest(directory_path)
with open("./models/manifest.json", "w") as manifest_file:
manifest_file.write(manifest_content)
print("Manifest file generated successfully.")
This is how to run it
python3 scripts/generate_manifest.py
Based on Existing NFT Collection
Handling Messy NFT Metadata
Oftentimes metadata traits in NFT collections will contain a bunch of special characters and may not always match 1:1 with the visual trait. In these cases you will want a higher abstraction level system if you want to do things like to match the original metadata filenames to renamed versions you're using when handling the actual assets.
First, we create a schema on how we go about renaming from the NFT metadata traits to a machine readable version with a CSV file containing every unique trait per row. For Anata project it looks like this:
Body,trait_type,Category,Original,Rename
Feminine,Brace,BRACE,Abstract Vision Brace,Abstract_Vision_Brace
Feminine,Brace,BRACE,Arrow Brace Blue,Arrow_Brace_Blue
Feminine,Brace,BRACE,Arrow Brace Fallen Angel,Arrow_Brace_Fallen_Angel
Feminine,Brace,BRACE,Arrow Brace Green,Arrow_Brace_Green
Feminine,Brace,BRACE,Arrow Brace Holy,Arrow_Brace_Holy
We include the body and category because we needed to rename the trait_type values too since some contained special characters and also because there were occasions where the same trait value showed up in different categories. We save this file as master_renamed_f
Then with this script we generate a manifest file per NFT ID, using the JSON of the original metadata + the CSV file containing original and renamed values as arguments like so:
import argparse
import csv
import json
import os
# Define the culling layer mapping
# -1 = always show
# 0 = usually body / skin
# 1 = will cull with 0 (so usually clothing)
# 2 = will cull with 0 and 1 (so usually hair)
# etc..
culling_layer_mapping = {
"Body": 0,
"Brace": 0,
"Clips and Kanzashi": -1,
"Clothing": 1,
"Earring": -1,
"Face Other": -1,
"Glasses": -1,
"Hair": 1,
"Hair Accessory Other": -1,
"Halos": -1,
"Hats": -1,
"Head": -1,
"Head Accessory Other": -1,
"Masks": -1,
"Neck": -1,
"Ribbons and Bows": -1,
"Sigil": -1,
"Tail": -1,
"Weapon": -1,
"Weapon Brace": -1,
"Wings": -1
}
def read_csv_mapping(csv_file_path):
id_mapping = {}
with open(csv_file_path, 'r') as csvfile:
csv_reader = csv.DictReader(csvfile)
for row in csv_reader:
original_name = row['Original']
renamed_name = row['Rename']
id_mapping[original_name] = renamed_name
return id_mapping
def get_animation_paths(directory_path):
animation_directory = os.path.join(directory_path, "_animations")
animation_paths = [os.path.join("./anata-vrm/_animations", file) for file in os.listdir(animation_directory) if file.endswith(".fbx")]
return sorted(animation_paths)
def get_id_from_mapping(trait_name, id_mapping):
# Get the original name directly using trait_name
renamed_name = id_mapping.get(trait_name, None)
return renamed_name if renamed_name is not None else trait_name
def create_manifest(input_file, csv_file, id_mapping):
"""
Generate a *_manifest.json file based on a given *_attributes.json file and a CSV file.
Args:
input_file (str): The input JSON file (*_attributes.json).
csv_file (str): The input CSV file.
This script takes an input JSON file (*_attributes.json) and a CSV file and generates a corresponding
*_manifest.json file with specific formatting. It maps trait types to culling layers
based on the culling_layer_mapping and creates the manifest accordingly.
"""
with open(input_file, 'r') as f:
data = json.load(f)
with open(csv_file, 'r') as csv_file:
csv_reader = csv.DictReader(csv_file)
name_mapping = {row['Original']: row['Rename'] for row in csv_reader}
folder_name = data["name"]
output_file = f"{folder_name}_manifest.json"
# Define the template for the manifest
manifest = {
"thumbnail": f"./anata-vrm/_thumbnails/t_{folder_name}.jpg",
"format": "vrm",
"traitsDirectory": f"./anata-vrm/male/",
"thumbnailsDirectory": f"./anata-vrm/male/",
"exportScale": 0.7,
"animationPath": get_animation_paths(directory_path),
"traitIconsDirectorySvg": "./assets/_icons/",
"requiredTraits": ["Body"],
"defaultCullingLayer": -1,
"defaultCullingDistance": [0.3, 0.3],
"offset": [0, 0.48, 0],
"initialTraits": ["Body", "Hair", "Clothing", "Head", "Face Other", "Clips and Kanzashi", "Neck", "Masks", "Glasses", "Hats", "Head Accessory Other", "Hair Accessory Other", "Ribbons and Bows", "Earring", "Wings", "Halos", "Tail"],
"traits": [],
"textureCollections": []
}
for attribute in data["attributes"]:
trait_type = attribute["trait_type"]
trait_value = attribute["value"]
original_name = attribute.get("Original") # Get the "Original" name from the attribute
renamed_name = attribute.get("Rename")
# Use the original name if available in the CSV mapping, otherwise use the trait_value
display_name = name_mapping.get(original_name, trait_value)
trait_entry = {
"trait": trait_type,
"name": trait_type.capitalize(),
"icon": "",
"type": "mesh",
"iconGradient": "",
"iconSvg": f"{trait_type.upper()}.svg",
"cullingLayer": culling_layer_mapping.get(trait_type, -1),
"cameraTarget": {"distance": 5, "height": 1.2},
"cullingDistance": [0.03, 0.03] if trait_type =="Body" else [0.3, 0.3],
"collection": [
{
"id": trait_value,
"name": trait_value,
"directory": "BODY/male.vrm" if trait_type == "Body" else f"{folder_name}/{get_id_from_mapping(renamed_name or trait_value, id_mapping)}.vrm",
"thumbnail": "BODY/male.png" if trait_type == "Body" else f"{folder_name}/thumbnails/{get_id_from_mapping(renamed_name or trait_value, id_mapping)}.png",
"textureCollection": "Body Skin" if trait_type == "Body" else ""
}
]
}
manifest["traits"].append(trait_entry)
# Append textureCollections for "BODY" trait
body_collection = {
"trait": "Body Skin",
"collection": [
{
"id": f"skin_{folder_name}",
"name": f"Eyes {folder_name}",
"directory": f"{folder_name}/skin_{folder_name}.png",
"thumbnail": f"{folder_name}/skin_{folder_name}.png"
}
]
}
manifest["textureCollections"].append(body_collection)
with open(output_file, 'w') as output:
json.dump(manifest, output, indent=2)
if __name__ == '__main__':
directory_path = "/home/jin/repo/anata-vrm/"
parser = argparse.ArgumentParser(description="Generate *_manifest.json file from *_attributes.json files")
parser.add_argument("input_file", help="Input JSON file (*_attributes.json)")
parser.add_argument("csv_file", help="Input CSV file with name mapping")
args = parser.parse_args()
id_mapping = read_csv_mapping(args.csv_file)
create_manifest(args.input_file, args.csv_file, id_mapping) # Include id_mapping argument
Can run on a folder containing JSON files from the chain like this:
for i in *.json; do python3 generate_manifest.py "$i" master_renamed_filenames.csv; done